我们首先简单介绍下Lucene:Lucene是用java实现的、成熟的开源项目,利用Lucene可以非常方便的为产品提供出全文检索的功能,比如IBM的开源软件eclipse也采用了Lucene作为帮助子系统全文索引引擎,相应的IBM的商业软件Web Sphere中也采用了Lucene。
今天带给大家的实例是我从apache官网找到的实例,因为自己也是第一次接触Lucene,所以费了挺大的功夫才搞清楚这个实例是怎么去用的,为了让更多像我这样情况的朋友能够快速的上手使用,所以我想分享这篇文章来帮助大家。
使用Lucene,主要分两大部分:
- 利用Lucene为你的资源建立索引文件,Lucene可以把索引文件存储在硬盘或内存中
-
用户输入搜索条件,Lucene会在指定的索引文件中查找到包含搜索内容的资源
为大家举个例子具体点介绍下:
在我的电脑上 F:\lucene-4.10.2\lucene-4.10.2\docs 这个路径下有很多的html以及txt的文本文件,我会用Lucene将这个目录下的所有文件索引,并将索引文件保存到 F:\lucene-4.10.2\index 这个目录下。我输入一个查询条件,比如"test"这个字符串,希望能找到所有包含这个字符串的文件(docs目录下有些文件的内容中包含该字符串),这样的话Lucene就会在索引文件中查找该字符串,并将查询结果以每页10条的分页结果显示出来。
需要用到Lucene4.10.2的jar包请到网盘下载:
http://yunpan.cn/cfkiHbwEwFicr 提取码 546e
1. 第一个java类,建立索引文件,源码如下,直接运行main方法即可建立索引文件:
package com.codingyun.core.util;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class CreateLuceneIndex {
public static void main(String[] args) {
if (args == null || args.length <= 0) {
args = new String[] {
"-index",
"F:\\lucene-4.10.2\\index",
"-docs",
"F:\\lucene-4.10.2\\lucene-4.10.2\\docs" };
}
String indexPath = ""; // 索引文件保存的路径
String docsPath = null; // 资源文件所在目录
boolean create = true;
for (int i = 0; i < args.length; i++) {
if ("-index".equals(args[i])) {
indexPath = args[i + 1];
i++;
} else if ("-docs".equals(args[i])) {
docsPath = args[i + 1];
i++;
} else if ("-update".equals(args[i])) {
create = false;
}
}
if (docsPath == null) {
System.err.println("资源文件所在目录为空,请指定资源文件所在目录!!!");
System.exit(1);
}
final File docDir = new File(docsPath);
if (!docDir.exists() || !docDir.canRead()) {
System.out.println("资源文件目录 '" + docDir.getAbsolutePath()
+ "' 不存在或不可读,请检查!");
System.exit(1);
}
Date start = new Date();
try {
System.out.println("建立索引文件到该目录 '" + indexPath + "'...");
Directory dir = FSDirectory.open(new File(indexPath));
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig iwc = new IndexWriterConfig(
Version.LUCENE_4_10_2, analyzer);
if (create) {
// 创建新的索引文件,删除所有其他的索引文件
//(指的是该资源文件目录下的旧的索引文件,其他资源的索引文件不影响)
iwc.setOpenMode(OpenMode.CREATE);
} else {
// 如果有旧的索引文件,则更新索引文件
iwc.setOpenMode(OpenMode.CREATE_OR_APPEND);
}
IndexWriter writer = new IndexWriter(dir, iwc);
indexDocs(writer, docDir);
writer.close();
Date end = new Date();
System.out.println(end.getTime() - start.getTime()
+ " total milliseconds");
} catch (IOException e) {
System.out.println(" caught a " + e.getClass()
+ "\n with message: " + e.getMessage());
}
}
/**
* 将资源文件索引到指定目录下,生成磁盘的索引文件
*
* @param writer
* 索引文件
* @param file
* 资源文件
*/
static void indexDocs(IndexWriter writer, File file) throws IOException {
if (!file.canRead()) {
return;
}
if (file.isDirectory()) {
String[] files = file.list();
if (files != null) {
for (int i = 0; i < files.length; i++) {
indexDocs(writer, new File(file, files[i]));
}
}
} else {
FileInputStream fis;
try {
fis = new FileInputStream(file);
} catch (FileNotFoundException fnfe) {
return;
}
try {
// 每一个文档最终被封装成了一个 Document 对象
// Document 是用来描述文档的,这里的文档可以指一个 HTML 页面,一封电子邮件,或者是一个文本文件。
// 一个 Document 对象由多个 Field 对象组成的。
// 可以把一个 Document 对象想象成数据库中的一个记录,而每个 Field 对象就是记录的一个字段。
Document doc = new Document();
// Field 对象是用来描述一个文档的某个属性的,比如一封电子邮件的标题和内容可以用两个 Field 对象分别描述。
Field pathField = new StringField("path", file.getPath(),
Field.Store.YES);
// pathField指的是资源文件的路径的field
doc.add(pathField);
// 这个field指的是最后的修改时间
doc.add(new LongField("modified", file.lastModified(),
Field.Store.NO));
// 把资源文件中的内容分词后,索引到索引文件中,指定为UTF-8编码
doc.add(new TextField("contents", new BufferedReader(
new InputStreamReader(fis, StandardCharsets.UTF_8))));
if (writer.getConfig().getOpenMode() == OpenMode.CREATE) {
System.out.println("adding " + file);
writer.addDocument(doc);
} else {
System.out.println("updating " + file);
writer.updateDocument(new Term("path", file.getPath()), doc);
}
} finally {
fis.close();
}
}
}
}
第一个java类执行后,控制台打印如下内容
adding F:\lucene-4.10.2\lucene-4.10.2\docs\test-framework\resources\titlebar_end.gif adding F:\lucene-4.10.2\lucene-4.10.2\docs\test-framework\serialized-form.html adding F:\lucene-4.10.2\lucene-4.10.2\docs\test-framework\stylesheet.css 13025 total milliseconds
2. 第二个java类,搜索内容,源码如下:
package com.codingyun.core.util;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
public class SearchFiles {
public static void main(String[] args) throws Exception {
args = new String[] {
"-index",
"F:\\lucene-4.10.2\\index"
};
if (args.length > 0
&& ("-h".equals(args[0]) || "-help".equals(args[0]))) {
System.exit(0);
}
String index = "index";
String field = "contents";
String queries = null;
int repeat = 0;
boolean raw = false;
String queryString = null;
int hitsPerPage = 10;
for (int i = 0; i < args.length; i++) {
if ("-index".equals(args[i])) {
index = args[i + 1];
i++;
} else if ("-field".equals(args[i])) {
field = args[i + 1];
i++;
} else if ("-queries".equals(args[i])) {
queries = args[i + 1];
i++;
} else if ("-query".equals(args[i])) {
queryString = args[i + 1];
i++;
} else if ("-repeat".equals(args[i])) {
repeat = Integer.parseInt(args[i + 1]);
i++;
} else if ("-raw".equals(args[i])) {
raw = true;
} else if ("-paging".equals(args[i])) {
hitsPerPage = Integer.parseInt(args[i + 1]);
if (hitsPerPage <= 0) {
System.err
.println("最少每页有1条数据");
System.exit(1);
}
i++;
}
}
IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(
index)));
IndexSearcher searcher = new IndexSearcher(reader);
// :Post-Release-Update-Version.LUCENE_XY:
Analyzer analyzer = new StandardAnalyzer();
BufferedReader in = null;
if (queries != null) {
in = new BufferedReader(new InputStreamReader(new FileInputStream(
queries), StandardCharsets.UTF_8));
} else {
in = new BufferedReader(new InputStreamReader(System.in,
StandardCharsets.UTF_8));
}
// :Post-Release-Update-Version.LUCENE_XY:
QueryParser parser = new QueryParser(field,
analyzer);
while (true) {
if (queries == null && queryString == null) { // prompt the user
System.out.println("输入查询关键字: ");
}
String line = queryString != null ? queryString : in.readLine();
if (line == null || line.length() == -1) {
break;
}
line = line.trim();
if (line.length() == 0) {
break;
}
Query query = parser.parse(line);
System.out.println("Searching for: " + query.toString(field));
if (repeat > 0) { // repeat & time as benchmark
Date start = new Date();
for (int i = 0; i < repeat; i++) {
searcher.search(query, null, 100);
}
Date end = new Date();
System.out.println("Time: " + (end.getTime() - start.getTime())
+ "ms");
}
doPagingSearch(in, searcher, query, hitsPerPage, raw,
queries == null && queryString == null);
if (queryString != null) {
break;
}
}
reader.close();
}
public static void doPagingSearch(BufferedReader in,
IndexSearcher searcher, Query query, int hitsPerPage, boolean raw,
boolean interactive) throws IOException {
// Collect enough docs to show 5 pages
TopDocs results = searcher.search(query, 5 * hitsPerPage);
ScoreDoc[] hits = results.scoreDocs;
int numTotalHits = results.totalHits;
System.out.println(numTotalHits + " total matching documents");
int start = 0;
int end = Math.min(numTotalHits, hitsPerPage);
while (true) {
if (end > hits.length) {
System.out
.println("Only results 1 - " + hits.length + " of "
+ numTotalHits
+ " total matching documents collected.");
System.out.println("Collect more (y/n) ?");
String line = in.readLine();
if (line.length() == 0 || line.charAt(0) == 'n') {
break;
}
hits = searcher.search(query, numTotalHits).scoreDocs;
}
end = Math.min(hits.length, start + hitsPerPage);
for (int i = start; i < end; i++) {
if (raw) { // output raw format
System.out.println("doc=" + hits[i].doc + " score="
+ hits[i].score);
continue;
}
Document doc = searcher.doc(hits[i].doc);
String path = doc.get("path");
if (path != null) {
System.out.println((i + 1) + ". " + path);
String title = doc.get("title");
if (title != null) {
System.out.println(" Title: " + doc.get("title"));
}
} else {
System.out.println((i + 1) + ". "
+ "No path for this document");
}
}
if (!interactive || end == 0) {
break;
}
if (numTotalHits >= end) {
boolean quit = false;
while (true) {
System.out.print("Press ");
if (start - hitsPerPage >= 0) {
System.out.print("(p)revious page, ");
}
if (start + hitsPerPage < numTotalHits) {
System.out.print("(n)ext page, ");
}
System.out
.println("(q)uit or enter number to jump to a page.");
String line = in.readLine();
if (line.length() == 0 || line.charAt(0) == 'q') {
quit = true;
break;
}
if (line.charAt(0) == 'p') {
start = Math.max(0, start - hitsPerPage);
break;
} else if (line.charAt(0) == 'n') {
if (start + hitsPerPage < numTotalHits) {
start += hitsPerPage;
}
break;
} else {
int page = Integer.parseInt(line);
if ((page - 1) * hitsPerPage < numTotalHits) {
start = (page - 1) * hitsPerPage;
break;
} else {
System.out.println("No such page");
}
}
}
if (quit)
break;
end = Math.min(numTotalHits, start + hitsPerPage);
}
}
}
}
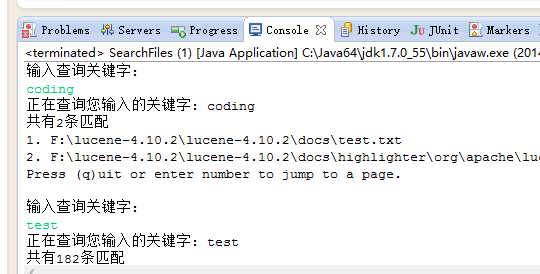
第二个java类执行后,控制台打印如下内容,输入关键字查询,找到符合条件的记录后,会打印出来。
注意:输入关键字查询,请不要用汉字输入法哦,请输入英文字符查询
希望能够帮助大家入门,谢谢各位,如果喜欢请点赞,或分享到您的微信、微博。。。
(转载本站原创文章请注明作者与出处Coding云--codingyun.com)